-2.jpg?width=240&height=83&name=Menu-Banner%20(5)-2.jpg)
.jpg?width=240&height=83&name=Menu-Banner%20(8).jpg)



What is an Enterprise Data Bus (EDB)? An EDB is a collection of data management and analysis tools that are installed and orchestrated so that the corpus of enterprise data is made available for analysis, and business value creation. An EDB is the analytics node of the data fabric. It can be used as an integration hub and connector layer of the data fabric. An EDB embraces the Dataops concept by allowing an agile method for automation and orchestration of the enterprise’s data journey, followed by Data from creation to its eventual use for deep analytics, data science, and automated business decisions.

While working with clients on their journey to becoming a data-driven enterprise, one of the key challenges encountered is the reliability of the data being used to drive business decisions. There is almost an unlimited amount of data available to an enterprise. It must be properly ingested, stored, transformed, and managed for it to be useful in business decisions, and digital transformations.
Many times we have seen Big Data and Data Science initiatives derailed. It did so due to the availability, reliability, and infrastructure performance issues that come with large data sets, which require very precise data quality. The concepts that are applied to Master Data Management need to be applied similarly to the source data for Data Science and Analytics studies. This means that many of the tools that are used for MDM can be leveraged within an EDB.
As the EDB evolves with more data sources, transformations, and workflows, it can be seen as part of the data fabric’s Enterprise Integration Hub. Here, many sources and consumers of data orchestrate data exchange through a common set of robust infrastructure.
As illustrated in the architecture discussion below, the EDB is designed in logical layers. These logical layers can be implemented in several physical configurations, depending on the need for scalability, extensibility, or performance of individual layers.
As with any complex architecture, planning is the best way to mitigate failure. It needs enough amount of time to be allocated to discuss business requirements and technology constraints before attempting a physical implementation of an EDB. Knowledge of the underlying tools chosen to implement the EDB is also crucial, and experience with big data and data integration projects will be useful. Start small and grow the implementation in increments.
The architecture will not change, but volumes and number of data sources and consumers need to be validated and managed as the implementation grows.
The EDB Architecture
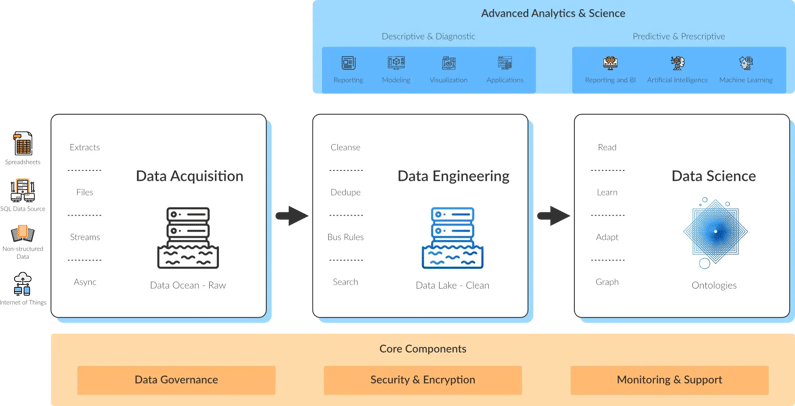
An EDB ecosystem is architected in layers. Each layer has its own set of scalable component services orchestrated in a manner to allow the best possible utilization of resources to create trusted analytics data. The EDB is built on top of the enterprise core components of Security, Monitoring, DataOps, and Data Governance.
By Implementing an Enterprise Data Bus, organizations can effectively gather their data in the Ingestion/Integration layer, store the raw, unfiltered data in the Data Ocean. From there, study data is transformed through the Data Engineering layer, and stored on the Data Lake as reliable, for purpose data. Once in the Data Lake, reliable and transformed data can be used for any number of analytics and data science purposes.
Not only can the EDB supply data to Data Science and deep analytics but, it can also be a trusted source for data warehouses, data marts, operational data stores, and other systems and applications that may need highly reliable data.
Since the EDB ecosystem can be bi-directional, results from analytics studies and AI can be used to act upon data in the source systems, creating better operational systems.
EDB by Layer
Source – These are sources of data that can be used for the enterprise data journey. They can be internal systems (CRM, ERP, MDM, SFA, etc.) or, external structured data (lead generators, demographic data, web transaction data, etc.) or, unstructured external data (posts to Yelp, Twitter tweets, Instagram photos, and comments), among others.
Ingestion/Integration – This layer provides the tools required to find, capture, and store the data into its initial landing site, the data ocean. There are several tools, all open source, included with the base implementation of the EDB. They are used to capture data from the sources, perform simple transformations to that data (such as convert to a common format, tag with metadata), and store in a format. The engineering layer can then access that. The benefit of this is, you can rapidly gather large amounts of data in a relatively raw state, and store it in a high - performance container (the Data Ocean) that is a cost-effective, scalable, and high volume infrastructure.
Data Ocean – This is a high-performance file system and data store that holds source data in its raw state for use with analytics or other data intelligence activities. This model allows fast, high volume data capture and storage. Its benefits allow capture of large data sets in a fast, cost-effective infrastructure, with the ability to provide large amounts of data quickly as needed by analytics, and business intelligence systems.
Data Engineering – In this layer, the raw data from the Ocean is transformed into for purpose data used by analytics and business intelligence projects. In the engineering layer, data is transformed using open source or proprietary tools for data matching, data cleansing, data type matching, language translation, and other several transformations required for later use. The output of this layer is in a form that is required for particular study use. This is the critical layer that requires clean, reliable data to use for analytics and BI studies. Without this key layer, a significant rework is required for studies, as data must be cleaned and corrected, which results in the cost of lost productivity hours and bad decisions made by the analytics studies.
Data created by the Engineering layer is stored in the Data Lake, this is clean and reliable data stored in a form that can easily be used by analytics tools.
Data Lake – This is another high-performance, high capacity data store, similar to the Data Ocean where cleaned, ready to use data is stored. It can also be used as a staging area for Engineering, analytics, and BI work as it progresses. The data lake, while almost identical to the Data Ocean in tools, is implemented in a separate compute space to allow for scaling without impacting the other layers of the Architecture. The benefit of this layer is to have a repository of clean and reliable data on which to run analytics studies. It saves significant time and cost by eliminating rework or poor decisions during the analysis process.
Analytics and Data Science – While this is the domain of the analyst and Data Scientist, the EDB provides the tools and connectivity that enables the Analytics teams. The tools, here, are typically specified by the analytics teams, and implementers as part of the EDB overall ecosystem. Any number of Ontology and Analysis Lakes can be created depending on the organization of the study groups.
Because the EDB connects all layers in a bi-directional manner, results from analytics studies can act upon source systems to add or correct data in their data stores.
Bottom Line - While many 360 degree tools typically focus on one domain (customer, product, etc.), MIT, by implementing EDB, MDM, and Ontologies, focuses on the entire domain of an enterprise by architecting the ecosystem required to get a true global view of their business domains and enable the data-driven enterprise through data engineering solutions.
