.jpg?width=240&height=83&name=Menu-Banner%20(3).jpg)




Our clients frequently complain that their understanding of their business is hampered by the fact that much of their vital data resides as ‘dark data’ in silos that don’t reside on traditional IT infrastructure (system data).
There are mountains of dark data sitting on people’s laptops, desktops, servers, and other corporate assets that go unused because they are embedded in cumbersome formats, often requiring a lot of manual intervention to load into modern digital data stores. This data includes PDF files, excel files, text files, log files, image files, etc., that are routinely generated during normal business operations. This data provides valuable context and may be critical to drive insights around the actual business process.
We developed the Smart Ingestion solution as a means of tackling this silent but critical issue that has long prevented many organizations from operationalizing their data.
The main problem with dark data is that it is defined by ‘unstructured’ (rather, semi-structured) information that doesn’t follow a standard template. For instance, if you examine any excel spreadsheet, you could find more than 1000+ ways to organize the same data in that spreadsheet while conveying the same information. The same is true of data found in PDF files. In fact, this is true of any data that humans transact with (or pass along) on a day to day basis in the course of their working day. There are thousands, millions (maybe even billions) of custom formatted reports that exchange hands over the course of a year in any given business. Apart from internally generated data, it is common that most transactional data exist in printed paper formats (e.g., receipts, invoices, bill of goods/materials/lading, etc.). The combinations are endless. By excluding such data, we would have a huge gap in our understanding and visibility of the business operations.
Traditional ETL methods and tools make use of a template to extract data from structured fields found in these documents. The problem with templates is that if the underlying information changes even a little the template becomes outdated/irrelevant/useless - For real world data ingestion, such manual techniques are unscalable and often very costly - It can take anywhere from hours to weeks to design templates for dark data ingestion, and due to the unregulated nature of the underlying data, there is likely to be a high degree of churn in those templates as the underlying data formats change due to factors beyond our control - For instance, you might receive data from a vendor in a particular format, and due to changes in their internal policies, this might impact the formatting of the documents they send you, even if it contains the same information as before, organized in a completely different way.
Alternately, if your vendor is acquired by another organization, their document headers might change, their addresses might change, etc. A templatized approach makes it very cumbersome to keep up with all this change.
We asked the question, “Is there a better way to do this, through AI?” It turns out, there is. Though such documents and data are subject to all sorts of change, there are certain aspects that are constant – for instance, how human beings read documents (in English) is unlikely to change. We exploit these intrinsic, unchanging (‘invariant’) features to rapidly ingest dark data, by encoding them in what we call a 'Seed Ontology’, and then use this Seed Ontology to mechanically extract and tag the data automatically - Magically, the data which was previously dark or inaccessible, is now expressible as a Knowledge Graph, revealing all kinds of interesting patterns as a result of exposing the hidden context within it.
The advantage of our approach over traditional machine learning solutions to this problem - is that our output follows the WYSIWYG principle: What You See Is What You Get - In other words, when you are reporting revenue numbers, you can’t report a fuzzy or uncertain number, especially when uncertainty arises from ingestion errors. You need to report an exact number. If your solution uses a traditional statistical learning-based classifier, it will result in false positives, false negatives, etc. Simply put, it will misclassify things and those misclassifications will flow right through into your reporting. Our solution bypasses this completely using a semi-mechanical AI-powered approach that enables us to replicate the underlying data and data-tags exactly, making it suitable for operational and financial reporting, as well enabling downstream analytics or data science requirements -
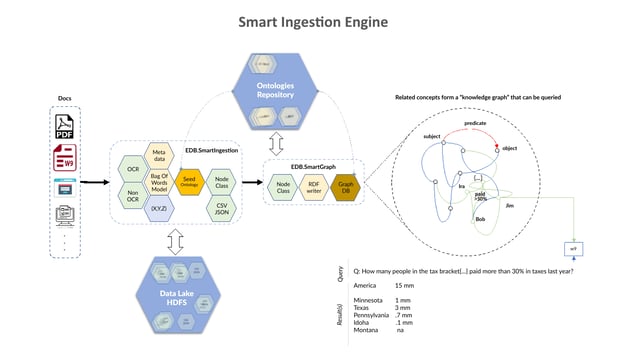
The limitations of OCR based pre-processing notwithstanding, our solution is superior to any other approach in digitizing dark data, making it the solution of choice for mission-critical reporting applications. When our client first saw the outcome of this approach, they remarked, “The fastest way to realize ROI in a single quarter is to partner with [MIT]!” The use of Smart Ingestion technology reduced the time/cost/effort of their manual data ingestion process by nearly 80%, and in turn, unlocked a substantial upside potential as the data is now accessible to analytics and data science - A key value-added outcome was the ability to validate the incoming data quality, for instance, the ability to incorporate a data validation step into the ingestion process where you could immediately see whether or not the line-item numbers in a claims report sum up to the total claim amount at the bottom of the page.
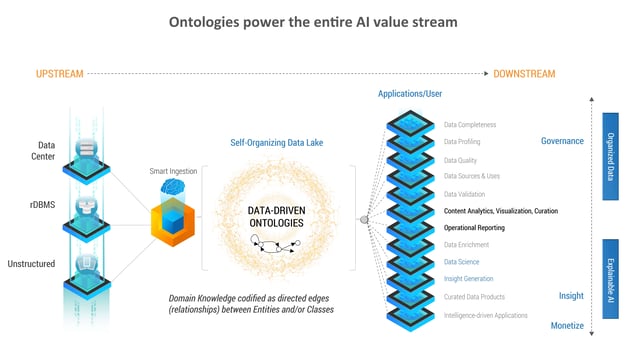
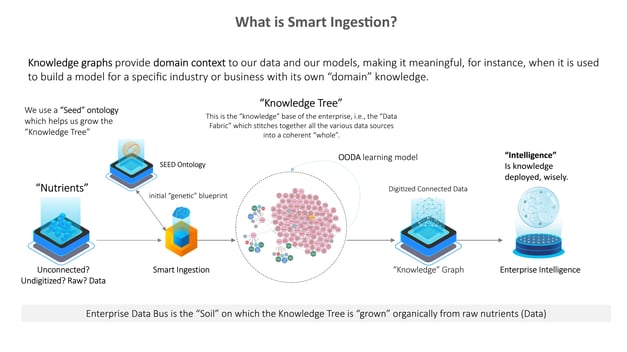
Today, this solution is evolving into the core element of the EIH, our Enterprise Intelligence Hub, which leverages data from the system, transactional, and other sources, to generate knowledge and insights that allow businesses to make data-driven decision a practical reality. The idea is that a simple Seed Ontology that has no domain intelligence can be used to ‘grow’ an enterprise knowledge tree (that encodes domain knowledge), through a self-organizing principle, that ultimately exposes the entire corpus of enterprise data to machine learning and AI, allowing all kinds of insights to develop.
Imagine data that organizes itself to power your decision-making.