-2.jpg?width=240&height=83&name=Menu-Banner%20(5)-2.jpg)
.jpg?width=240&height=83&name=Menu-Banner%20(8).jpg)



An enterprise data lake for modern analytics and business intelligence (BI) involves storing and processing large volumes of diverse data in a centralized repository, enabling flexible and scalable analytics capabilities. This blog will cover key components for building an enterprise data lake platform foundation and designing a data lake architecture for modern analytics and Business Intelligence.

Platform foundation
When building a data lake architecture, it's important to establish solid foundations to ensure its effectiveness, scalability, and maintainability. Below are some key considerations for establishing the foundations of a data lake architecture platform.

a. Infrastructure platform
Determine whether you will build your data lake On-Prem or in the Cloud. Cloud-based platforms such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP) offer scalability, flexibility, and managed services that simplify data lake setup and management.
b. Foundational services
1. Compute resources - If you choose to deploy on Cloud, multiple Cloud platforms like AWS, Azure, and GCP offer scalable compute resources. You can provision virtual machines (VMs) or use managed services like AWS Elastic Compute Cloud (EC2), Azure Virtual Machines, or Google Compute Engine. These services allow you to scale up or down based on demand.
2. Storage - Cloud-based object storage services like Amazon S3, Azure Blob Storage, or Google Cloud Storage are popular choices for Cloud-based data lakes. These services provide scalable and durable storage options with pay-as-you-go pricing.
3. Operating system - Cloud platforms provide pre-configured images with various OS options for Cloud-based data lakes. You can choose the OS that best fits your needs and is supported by the cloud provider.
4. Networking - Cloud providers offer networking services for Cloud-based data lakes to establish connectivity within the data lake. You can configure virtual networks, subnets, security groups, and network access control lists (ACLs) to secure communication between different components. Consider using VPN or Direct Connect services to establish secure connections between on-premises and Cloud environments.
c. Data platform ecosystem
1. Storage - Choose a scalable and cost-effective storage solution for your data lake platform. Options include Hadoop Distributed File System (HDFS), Cloud-based object storage (e.g., Amazon S3, Azure Blob Storage), or a combination of both. Consider factors like data volume, access patterns, performance requirements, and data durability.
2. Execution engine - Choose the appropriate processing framework for your data platform. Apache Spark is a popular choice for large-scale data processing and analytics. It supports distributed computing, data transformation, machine learning, and streaming.
3. No-SQL database - No-SQL databases play a significant role in a data lake platform, especially when managing and processing semi-structured and unstructured data. No-SQL databases, such as MongoDB, Cassandra, or Apache HBase, are designed to handle flexible and schema-less data structures. They excel at storing and retrieving semi-structured and unstructured data, such as JSON, XML, key-value pairs, or documents.
4. Graph repository - Graph databases like Neo4j, Amazon Neptune, or Janus Graph are designed to efficiently store and query graph-structured data. They are useful for applications that require analyzing complex relationships and graph-based algorithms.
d. Analytics, AI & ML ecosystem
1. AI & ML - AI and ML algorithms can assist in data exploration and preparation tasks within the data platform. Natural language processing (NLP) techniques can be applied to extract valuable information from unstructured data sources such as text documents or social media feeds. ML-based algorithms can help identify data patterns, outliers, and correlations, facilitating data cleansing, feature engineering, and data transformation processes.
2. Analytics and BI - Visualizing data is essential for understanding complex patterns, trends, and relationships within the data lake. Visualization tools like Tableau, Power BI, or custom-built dashboards enable users to create interactive visualizations and reports. These tools can be directly integrated with the enterprise data lake platform to provide real-time visual insights, making it easier for business users to interpret data and make informed decisions.
e. Core Services
1. Security and encryption - Implement strong security measures to protect data within the data lake. This includes encryption at rest and in transit, authentication mechanisms, access controls, and monitoring/logging of data access and activities. Regularly review and update security policies to address emerging threats and vulnerabilities.
2. Data governance - stablish practices to ensure data quality, security, privacy, and compliance within the data lake. Define policies for data access controls, data classification, data lineage, and data retention and implement data cataloging, metadata management, and data stewardship mechanisms.
3. Backup and disaster recovery - Implement robust backup and disaster recovery mechanisms to protect data in the data lake. Regularly backup data, metadata, and configuration settings. Establish data restoration and recovery procedures in case of data loss or system failures.
Reference architecture
The reference architecture for constructing a successful data lake can be divided into five main areas: Core Components, Data Acquisition, Data Engineering, Data Science, and Advanced Analytics & BI.
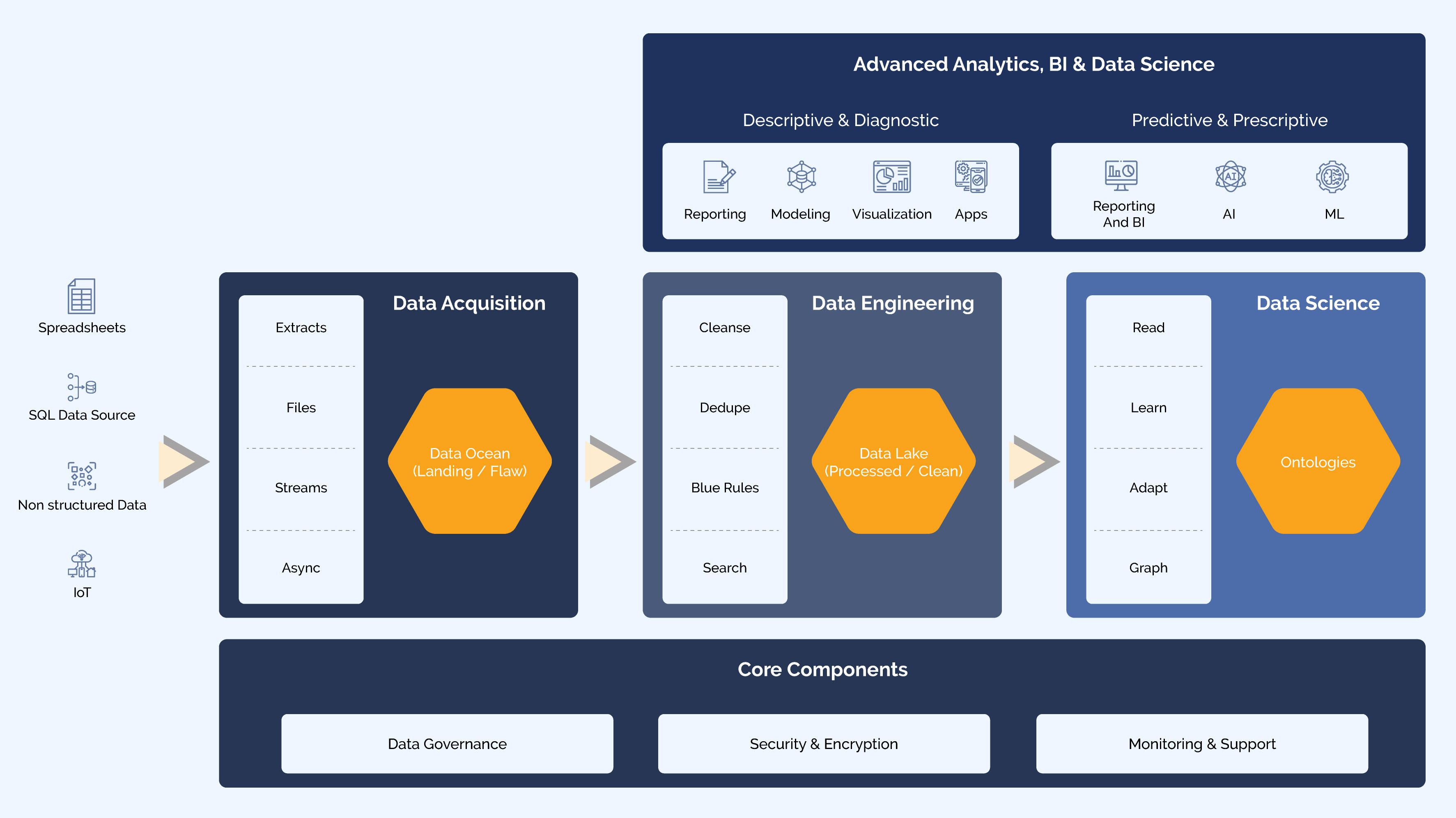
a. Core Components
1. Data governance - Implement practices to ensure data quality, security, compliance, and privacy. Define policies and procedures for data access controls, classification, lineage, and auditing to maintain data integrity and regulatory compliance.
2. Data security - Apply robust security measures to protect sensitive data in the data lake. This includes access controls, encryption, authentication mechanisms, and monitoring/logging to detect and prevent unauthorized access or breaches.
3. Monitoring and support - Establish monitoring and performance optimization practices for the data lake platform. Monitor system health, data quality, performance metrics, and resource utilization. Implement query optimization, data partitioning, caching, and indexing mechanisms to improve query performance.
b. Data Acquisition
1. Data ingestion - Data is ingested from various sources, such as transactional databases, logs, social media, and external APIs. Consider using tools like Apache Kafka or Apache Nifi to collect and process data in real-time or batch mode efficiently.
2. Data storage - Data lakes typically use distributed file systems like Hadoop Distributed File System (HDFS) or Cloud-based storage like Amazon S3 or Azure Data Lake Storage. These systems provide scalable and cost-effective storage for large volumes of data.
c. Data Engineering
1. Organizing data - Instead of enforcing a predefined schema, data lakes use a schema-on-read approach. Raw data is stored as-is, and the structure and schema are applied during data processing or analysis. Data can be organized into folders, partitions, or metadata tags for efficient retrieval.
2. Data catalog - Implement a metadata management system to provide a searchable inventory of data assets in the data lake. This helps data consumers discover and understand available datasets, including their structure, lineage, and quality.
3. Data processing - Perform data processing tasks like data cleansing, transformation, enrichment, and aggregation within the data lake. Apache Spark, Apache Hive, or Cloud-based services like Amazon Athena or Azure Databricks are commonly used for processing large datasets.
4. Data integration - Integrate the data lake with other analytics platforms or data warehouses to support hybrid architectures. This allows you to leverage the data lake for exploratory analysis while enabling structured analytics and reporting using tools like SQL-based analytics engines or BI platforms.
d. Data Science
1. Data Science and Machine Learning - Leverage the data lake to support advanced analytics and machine learning initiatives. Using frameworks like TensorFlow or PyTorch, data scientists can access and explore diverse datasets for model training, feature engineering, and predictive analytics.
2. Graph data - Based on use cases where complex relationships need to be derived, or the performance of traditional traversing paths is slow, the data from the lake can be loaded into Graph DB with a defined schema, map data to graph model, prepare extracts and load using graph DB's loading techniques.
e. Advanced Analytics and BI
1. Analytics and BI tools - Connect analytics and business intelligence tools to the data lake to enable self-service data exploration, visualization, and reporting. Popular tools include Tableau, Power BI, QlikView, or custom-built dashboards using frameworks like Apache Superset or Redash.
Conclusion
Establishing a robust foundation for a data lake platform sets the stage for efficient data management, advanced analytics, and data-driven decision-making. Building a successful data lake on top of the platform foundation requires careful planning and consideration of factors such as data governance, data quality management, and performance optimization. It also necessitates a collaborative effort among stakeholders, including data engineers, data scientists, business analysts, and IT teams, to ensure the data lake meets the organization's needs and aligns with its strategic goals.
Overall, a properly implemented data lake with robust platform foundations and architecture empowers organizations to harness the full potential of their data, enabling them to make informed decisions, uncover valuable insights, and drive business growth in the era of modern analytics and BI.
Related Webinar