-2.jpg?width=240&height=83&name=Menu-Banner%20(5)-2.jpg)
.jpg?width=240&height=83&name=Menu-Banner%20(8).jpg)



Overview
Retail chains that have brick-and-mortar stores, as well as online platforms, often struggle to identify the customers visiting their sites. Even with all the information available at their disposal, the probability of identifying the customers accessing their website is a mere 30%.

This blog discusses the system used to tracking and identifying customers who interact with our client’s online portal and then shop in-store and vice-versa.
Benefits
Identifying the change in customer preference based on the changes in climate and geography and its impact on the customer’s buying patterns is possible only if the system can synthesize fragments of customer data existing in data lakes and create a customer 360 view.
Identifying potential correlations of these factors with their buying pattern would enable our clients to target potential customers with more relevant marketing messages and customized offers.
Building the Data Lake using Big Data Technology
The above-stated benefits can be addressed by crunching historical data and performing advanced predictive analytics on top of it. With different forms of data coming in from multiple channels across the organization, having a single location that can hold all the data is desirable.
This calls for a Data Lake implementation that can be had as a foundation for running the analytics program. After reviewing several potential vendors who could implement a Data Lake, InfoTrellis was chosen based on a successful proof of concept delivered by InfoTrellis.
A managed Data Lake was built using Big Data Technology centered on Hadoop, which can hold multi-channel data of various formats. This Data Lake supports the ongoing scheduled and ad-hoc analytics by different teams across various functions of the client. It will also serve as the foundation for all analytic and reporting activities in the future. Our team assisted the Marketing IT team of the client with the design and ingestion of a huge volume of customer and marketing data into the Data Lake.
Data Lake Architecture
Over the course of the project, InfoTrellis ingested data from over 40 different data sources, bringing in over 100TB of data into the Data Lake. Data Sources were either near-real-time or scheduled batch. The ‘near-real-time’ data had to be handled “as soon as possible” but without a strict latency requirement.
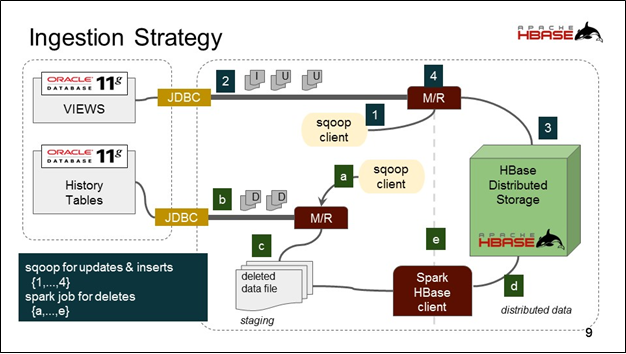
Data Lake Architecture
The Scheduled batch was handled on an ingest schedule (daily) either from a flat file or a relational database. Sqoop was used to ingest data from RDBMS sources, whereas Spark was used to read flat files and also to do mutation on these data. HBase was the preferred storage, though HDFS was also used extensively. The complete system was built on AWS with a cluster size of 24 nodes.
The Data Lake has been designed with due diligence to ensure that any future data sources to be added, regardless of the type of data source, can be handled by the system and it will be just “plug and play”.
Datameer – Analytics and Reporting Tool
Once the client decided upon having Datameer as their analytics and reporting tool, InfoTrellis worked with the client for the necessary data preparation work and also built the foundation of their predictive analytics and reporting activities. InfoTrellis’ Datameer experts also developed a roadmap with multiple use cases for the client, showcasing how Datameer could be used more extensively to gain better customer insights, which could help them in making strategic business decisions. This roadmap also acts as a guideline for effective future implementation of Big Data programs, Data governance, and tools usage.
InfoTrellis further spent over 100 hours of hands-on classroom training on Datameer for the client business and technology groups to enable the users to leverage Datameer and perform ad-hoc analytics on their data lake.
Conclusion
Successful implementation of the Data Lake and Datameer has enabled businesses to collate data from across different functions and draw insights from it based on analytics being run on top of it. This has ultimately resulted in the client being able to understand customer preferences better and provide them with more relevant offers.