
Overview
Data is siloed across wide variety of platforms in an enterprise environment and the data needs to be processed, cleansed, and mastered to ensure it is same across source systems for effective reporting and analysis. To cater to this need, Informatica provides Master Data Management (MDM) product called Multi-Domain Edition (MDE). To master the data in this tool, the data needs to be loaded into the Informatica MDM Hub. InInformatica MDM data can be loaded in two different modes (i) Batch and (ii) Real-time.
In this blog we will delve into Batch Processing for loading the data into the Informatica MDM Hub Store, and the various features and options that are available. Before diving into the batch process, let’s understand how data is organized in Informatica MDM Hub Store.

About MDM Hub Store
Informatica MDM Hub follows three layered approach, typically seen in an Extract, Transform and Load (ETL) process, to load the data.The layers are:
- Landing – This forms a pre-staging layer, tables in this layer are used to receive batch loads from multiple source systems.
- Staging – Tables in this layer are used to hold cleansed and standardized data before loading to the final target.
- Target – Tables in his layer, referred to as Base Objects (BO), contain the master data or golden records.
These tables and other related objects, along with master data, content metadata, rules for processing the source data and rules for defining the master data are stored in a database called as Operational Reference Store or ORS.
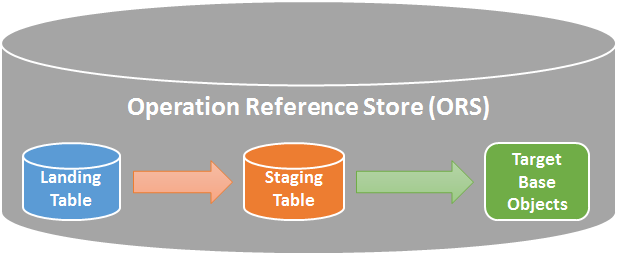
Figure 1: Informatica Hub Store
Batch Process
Informatica MDM Hub provides a sequence of steps and options to load the data, maintain lineage of data for tracking other metadata for effective processing and finally consolidate the data to build the Best version of Truth (BVT). Let’s look at the batch processes at a high level and understand the features they offer.
Land Process
Land Process is external to Informatica MDM Hub and is executed using external batch processes or external applications that directly populate landing tables in the Hub Store.
Land Process is optional and can be skipped, along with other Land Process options, as discussed in our blog, How to integrate Informatica Data Quality (IDQ) with Informatica MDM.
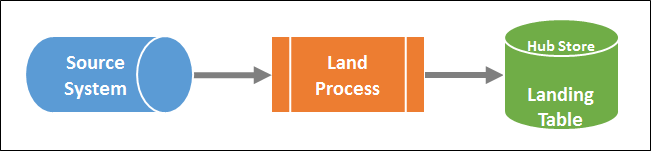
Figure 2: Land Process
Stage Process
Stage Process transfers source data from a “landing table to source specific staging table” associated with a base object. The movement of data from the landing table to the staging table is defined using Mappings offered by Informatica MDM Hub.
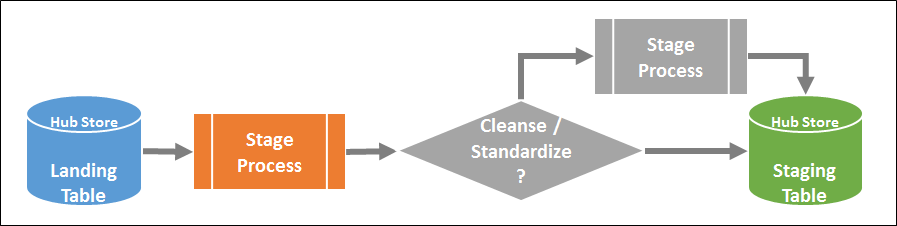
Figure 3: Stage Process
Mappings
Mappings define the movement of data from the source column in the landing table to the target column in the staging table. Data from landing table is cleansed and standardized before loading to staging table. The cleansing and standardization can be done within Informatica MDM HUB or outside using external tools like Informatica Data Quality (IDQ) or Informatica Power Center.
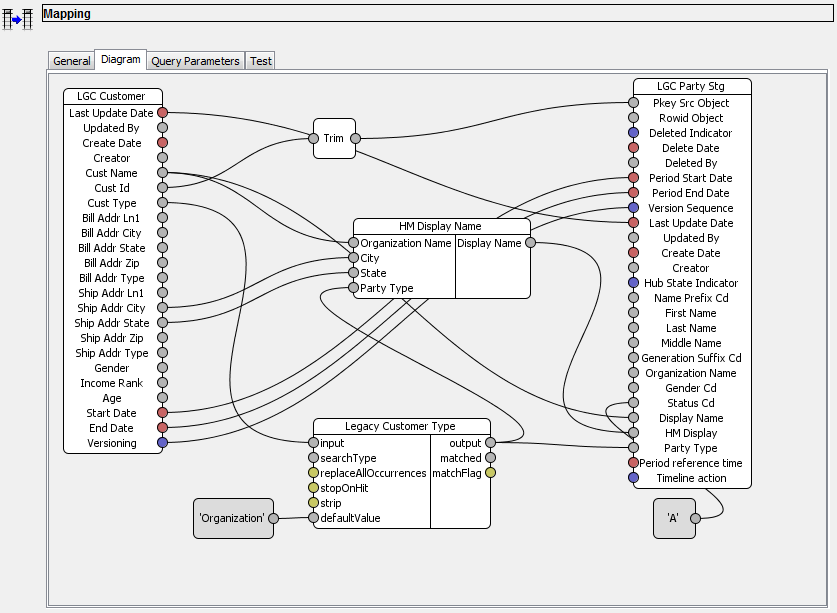
Figure 4: Landing Table to Staging Table Mapping
Reject Records
During the Stage Process, records that have problems are rejected and transferred along with the reason for rejection to the Reject Table associated with the Staging Table. If there are multiple reasons for rejection, the first reason alone is persisted.
Advantages of this feature
This feature helps investigate the rejected records after running the Stage Process. As this feature is built into Informatica MDM, it saves considerable development and implementation time.
Audit Trail
Stage Process is capable of maintaining a copy/replica of source data in a table (called as RAW table) associated with each of the staging tables. This is possible only if audit trail is enabled for the staging table for configurable number of stage job runs or retention period.
Advantages of this feature
This feature is useful for auditing purposes and tracking data issues, identifying the missing data back to the source data. Informatica MDM Hub provides this feature with an easy configuration, saving considerable development and implementation time.
Delta Detection
Stage Process can detect the records in the landing table that are new or updated if delta detection is enabled for a staging table. The comparison for delta detection can be configured based on all columns or for any date column or a specific set of columns as required.
Advantages of this feature
This feature is useful, if the data sent by source system is a full datset, to limit the volume to changed data only and thus improve performance in further processes.
Load Process
Load Process moves data from staging table to the corresponding base object. In addition to this, Load Process performs lookup, computes the trust score for merging of data and running the validation rules. Each base object has tables associated with it to capture the lineage of data, track the history of changes and other details.
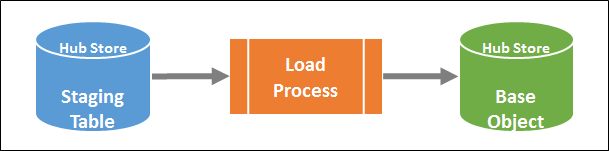
Figure 5: Load Process
Reject Records
During the Load Process, records are rejected and transferred along with reason for rejection to the Reject Table associated with Base Object’s Staging Table for that source system.
Advantages of this feature
This feature is based on cental reject table for maintaining reject records for both Stage & Load Process. Informatica knowledge base article KB 90407 provides a good insight into the reject handling process.
Tokenize Process
The tokenization process generates match tokens and stores them in a match key (strip) table associated with the base object. The match tokens are subsequently used by the Match Process to identify suspects for matching.
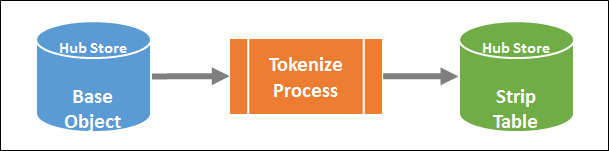
Figure 6: Tokenize Process
Match and Consolidate Process
Matching is the process of identifying whether two records are similar or duplicate of the other either by exact (deterministic) or fuzzy (probabilistic) matching.
Consolidation is the process of consolidating data from matched records into a single, master record once the match pairs or suspects have been identified in the Match process. Records can flag for auto merge if the suspects are sufficiently similar or sent for manual merge if suspects are likely to be duplicates.
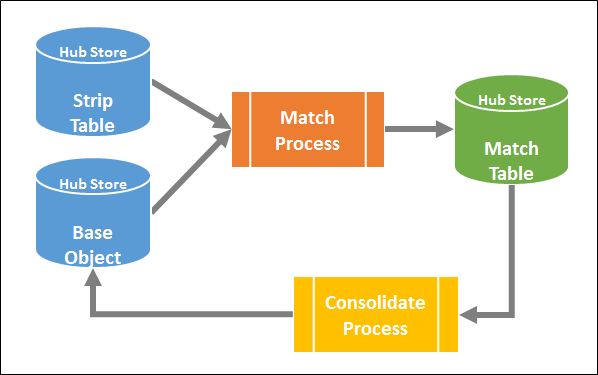
Figure 7: Load Consolidate Process
Summary
The following figure provides a detailed perspective on the overall flow of data through the Informatica MDM Hub using batch processes, including individual processes, source systems, base objects, and support tables.
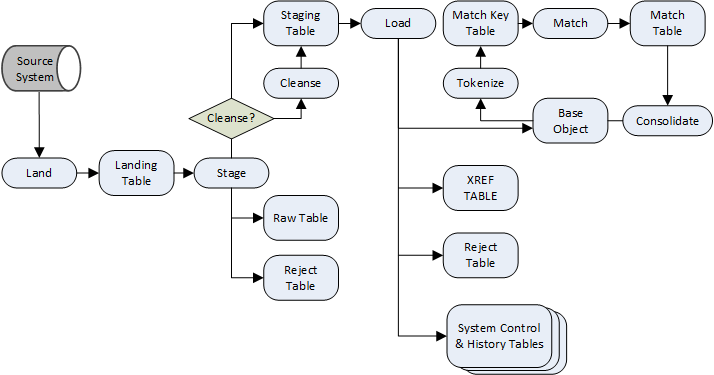
Figure 8: Informatica MDM MDE Batch Process (Image source: Informatica)
In Informatica MDM, Batch mode is often used for initial data load (first time business data is loaded), as it can be the most efficient way to populate large number of records. Batch mode provides necessary options and logic for loading data, updating the lineage of the data, and other metadata for processing the data.