-2.jpg?width=240&height=83&name=Menu-Banner%20(5)-2.jpg)
.jpg?width=240&height=83&name=Menu-Banner%20(8).jpg)



IIS Tool Suite Overview
As per a study conducted by a leading market research and advisory company, the data that we have generated in the past two years is many times more than that we generated in over two decades. It has not just multiplied but has also become complex and varied and is being generated at a much faster rate than it ever was. These factors present a data integration challenge to the industries and businesses to be able to better utilize their data for help building strategies, provide services, introduce policy regulations such that their business is empowered to bridge or completely meet the gap for that matter between data and analytics.
IBM has always been innovative, technology-driven and in fact, they pioneer in data integration and management technologies. They have always provided the business with the right set of tools and IBM MDM (Master Data Management) is the best example of that. Besides MDM, IBM also has IIS (InfoSphere Information Server) in its quiver to target data integration and management challenges that almost every line of business in this age encounters.
This blog aims to provide an outlook on the IBM IIS suite and how it can empower your business data integration demands for better resource utilization and finding the right set of tools to address key business challenges.
IIS Tools Suite
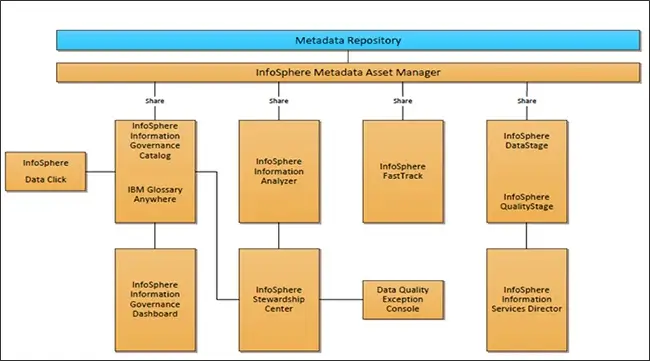
Figure 1: IIS Tool Suite
Interpreting the Suite
The following are the components listed in the suite:
Metadata Repository
Metadata repository is not a tool rather it is an architectural tier. Hence this tier has been represented in a different color. The metadata repository tier hosts the repository of InfoSphere Information Server; it exists as its own schema in this database. The repository is a shared component that stores operational metadata like design-time, runtime, glossary, rules defined, etc.
To better understand the role of each of these tools, let us briefly see what each of these can do.
InfoSphere Asset Manager
As the name suggests, you manage your enterprise metadata using the metadata asset manager. The metadata asset manager is a browser-based tool that runs smoothly over any of the modern web browsers. Use this tool to import, export and manage the common metadata that is vital to all the other suite products that work over metadata.
The enterprise metadata, when shared to metadata repository via metadata asset manager, becomes available to users of the other suite tool which can then be used in DataStage jobs, in the analyzer to be analyzed, in the governance catalog for assigning assets.
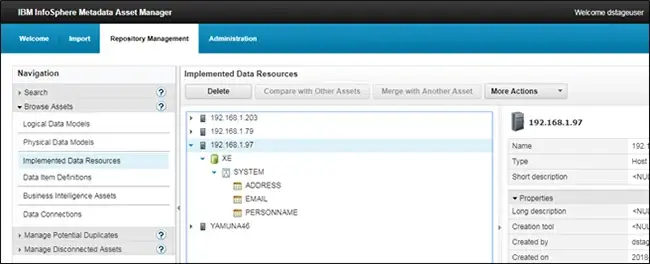
Figure 2: IBM Infosphere Metadata Asset Manager
Key features:
- If your organization has metadata project leaders and/or a data analyst then they can use this tool to import what is relevant to the IIS and restrict a developer from accessing trivial schemas, databases, columns, etc.
- The tool comes with a built-in staging area which is a separate schema within metadata repository. It allows you to analyze the imported contents, fix any duplicate metadata or identity issue and then reimport. It also allows you to preview the imports before it is shared to the repository thereby giving you a complete confidence in the enterprise metadata shared.
- Metadata Asset Manager can only be accessed by users with appropriate metadata user privileges.
InfoSphere Information Analyzer
This tool can help you understand the quality of your data, which in turn helps you to gain confidence in your data. If your organization, despite having a data integration, is facing anomalies in data, thereby decreasing the quality of data and causing more and more exceptions, then it is possible that the business rules and the transformation rules have not been framed with a complete understanding of data. This is where Information Analyzer (IA) is useful.
IA helps you to assess the data quality, identifying inconsistencies and redundancies at the column and cross-table level. It also allows you to create custom basic data rules, which you can run against a full volume of organizational data or a sample of data and get an insight on the exception even before the data reaches the integration layer. This will help the business analysts and data quality specialists to align the data quality metrics.
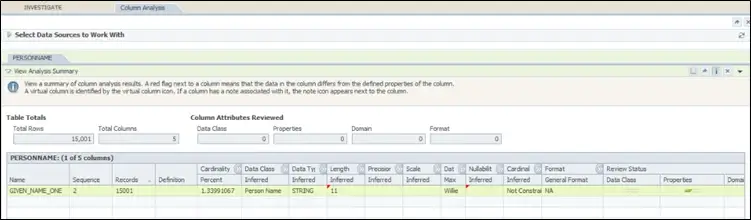
Figure 3 - A sample Column Summary in IA
Key Features:
- Full-data volume or sample data can be used for analysis.
- Can perform Column Analysis, Primary Key Analysis, Natural Key Analysis, Foreign-Key Analysis, Cross-domain Analysis and Base-Line Analysis. I will cover details for each of these types of analysis in another blog or you may reach out to us for a demo on request.
- Can generate various types of built-in reports based on the different analysis performed. These reports can be generated in different formats like HTML, pdf, excel, etc. and support different languages.
- The rules created in IA can directly be used in DataStage jobs.
InfoSphere FastTrack
This tool is the most underrated tool of the suite, but if properly utilized, it can catapult an integration project, reducing the time taken by the IT to develop the code and implement a basic level of business checks and transformations. FastTrack eliminates tedious copy and paste from various documents that are maintained to provide specifications to a developer. It links varied information and makes it available on the metadata repository for IIS rather than being shared in excels.
This tool best suits a business analyst and can help him to accelerate the design time of source-to-target mappings by automatically generating DataStage jobs allowing the developers to focus on more complex logic.
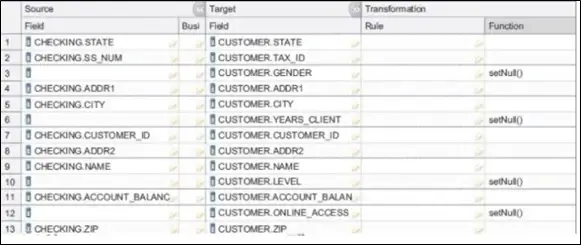
Figure 4 - A mapping specification sample in FastTrack (image source: https://namitkabra.files.wordpress.com)
Key features:
- It enables you to discover table column relationship, link glossary terms with columns and generate DataStage jobs.
- Considerably reduce the time and effort for maintaining different versions of source-to-target mapping
- Acts as a self-service platform that allows users to use excel like logics and automatically create DataStage jobs without having coding skills in DataStage
- The jobs created can act as a starting point or as a template for a DataStage developer defining how to build applications
InfoSphere DataStage and QualityStage:
This platform is one of the most powerful integration platforms. The secret sauce of this is the parallelism and pipelining framework which can be either on-premise or on a cloud. It is highly flexible and scalable and provides integration heterogeneous sources, including Hadoop and Stream-based, on both distributed and mainframe platforms. IT provides end to end integration quickly and enables you to cleanse, transform, monitor and deliver data anytime anywhere.
It can also provide data standardization, data quality investigation using its probabilistic matching and dynamic weighting strategies across geographies.
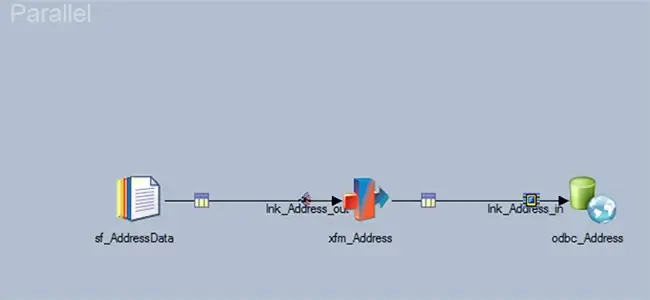
Figure 5: Sample DataStage Parallel Job
Key features:
- Enterprises can use its MPP engine to run natively in Hadoop thus providing speedier integrations in a big data platform including critical security features, such as Kerberos and secure gateways.
- Packs a unique feature “DataStage Balanced Optimization” which helps to fully harness available resources by utilizing computing power to your relational databases.
- Supports direct integration with Amazon S3 storage to load data into and from the cloud. Also, you can integrate seamlessly with REST applications, web services, XML and JSON messages.
- Provides a common client tool for integration (DataStage) and data enrichment (QualityStage) helping your organization to integrate, match and standardize, cleanse, govern data quality exceptions.
- Offers end-to-end integration with other suite tools leverages shared metadata content, unified installation, and deployment.
InfoSphere Information Governance Catalog:
Referred as IGC for short this tool becomes the start of any enterprise-level data analysis and integration projects. IGC is a browser-based tool capable of providing a marquee of functionalities to an organization to be able to understand and govern its information.
Often in any large organization information does not flow in right context end to end and among divisions. This causes a lot of discrepancies within the organization and very soon everyone starts making notions and conclusions as they deem fit. This is simply a nightmare for any business.
IGC provides the business and IT staff to use common terminology thus securing the information. The catalog comprises of glossary assets which are assets created within IGC and information assets that are linked or imported from other IIS applications via the shared metadata.
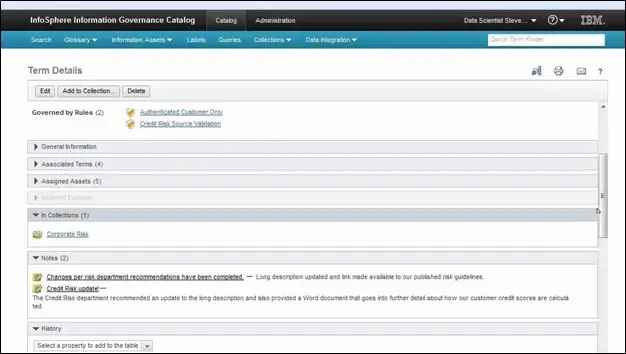
Figure 6 - A snapshot of editing a term created in IGC
Key Features:
- Provides lineage reports which enable business analysts to see the information’s origin and point of consumption as well as identify how the information was modified by the integration layer.
- It allows you to attach rules created in IA to the assets in IGC thereby enhancing the governing process.
- It follows a workflow-like process for creation, revision and publishes any changes that are made therefore, all the users are aware of the changes and the data specialist, as well as business analyst, can review the changes to either publish or reject.
- With the separately licensed” InfoSphere Glossary Anywhere client” you can browse glossary content from any desktop without logging into IGC. This tool provides the capability to search glossary for single words or phrases from any text-based document opened in a Windows desktop. The license is bundled with REST API that has the same search capabilities.
Information Governance Dashboard
IGD is used to evaluate, assess and monitor the governance policies and rules assigned in IGC. You can also query and visualize various types of metadata cataloged by IIS products. The dashboard provides elements such as SQL views, set of predefined Cognos reports and workspaces and a Cognos framework manager that you can use to understand the classes and relationships that contribute to a report.
Key Features:
- You can use SQL views to create reports independent of any tool or to use a different reporting tool other than Cognos.
- The included Cognos reports can be used to assess governance progress and customize reports
- You can monitor exceptions by using links into Data Quality Exception Console and IBM Stewardship Center to review and process exception sets and correct the exception records
Information Services Director
ISD allows the users to rapidly deploy their Information server logic into services which are deployed locally in your application server. For example, you created a DataStage job that integrates data from various source systems and now an external application wants to consume that data for order entries. This can be easily achieved by ISD.
Key Features:
- It provides the data to the business, users, and processes to be available anytime and all time
- It acts as an abstraction and encapsulation layer that hides all the complexities of the implementation from the service that consumes published data
- The integration service once enabled can be invoked by using a binding protocol like web service, REST or RSS.
InfoSphere Data Click
Building a data lake is an innovative way to utilize organizational data for better reporting and advanced analytics. Organizations that are trying to build a data lake (which is built over a Hadoop or other big data platform system) usually adopt a hybrid system that combines both Hadoop and relational databases. This requires some of the data/systems to be migrated to Hadoop system and here Data Click can help your organization. Data Click is a self-service tool that provides on-demand data integration; it is a separately installed add-on component of InfoSphere BigInsights.
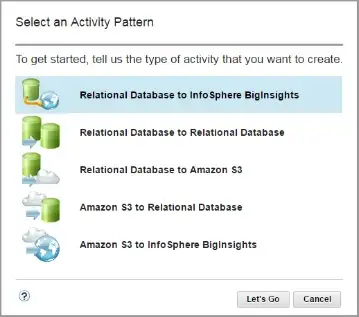
Figure 7 - Shows different supported migration
Key Features:
- Data click provides integration by creating activities; these activities are created using its browser-based tool. You can choose from a wide variety of source systems and target system and can provide conditions to limit data.
- If the target is a Hadoop system, then Data Click automatically creates Hive tables for each table of the source in the target directory.
- Data Click can also be used for relational database migration projects as well, for e.g. from Oracle to SQL Server.
InfoSphere Stewardship Console and Data Quality Exception Console
IBM Stewardship Center is a browser-based tool that leverages the strength of IBM Business Process Manager. Stewardship Center provides a process designer view to configure the BPM workflows. Data Stewards have become increasingly responsible to improve the data quality to provide value to their data assets. Using Stewardship Center, data stewards can address the data quality and governance challenges.
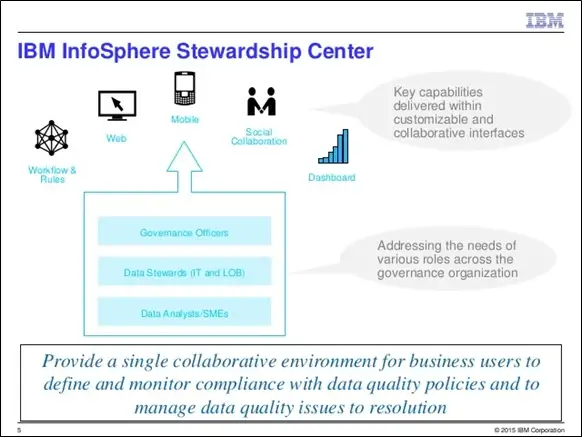
Figure 8: IBM InfoSphere Stewardship Center (Image Source: (IBMInfoSphereUGFR )
Key Features:
- IBM Stewardship Center is divided into three categories: data quality exception management, governance, and workflow notification, and performance metrics
- Stewardship is coupled with IGC and IA that include pre-built workflows to notify stewards of any asset activities and allow them to approve or reject rule changes
- The Data Quality Exception console can display the exceptions and exception records generated from any non-compliance with a rule in IA. All projects, jobs or rules that generate exceptions can send the exception to the console
- You can manage the priority of the quality issues in the exception console and manage those exception sets with different BPM process applications in Stewardship Center
Conclusion
IBM Information Infosphere offers the above tools to build data integration and management services for large-scale enterprises. These tools help you to understand, cleanse, transform and deliver unified, trusted enterprise-wide data to your critical business.