-3.jpg?width=240&height=83&name=Menu-Banner%20(2)-3.jpg)
-3.jpg?width=240&height=83&name=Menu-Banner%20(1)-3.jpg)



Overview
Data Warehousing has been the buzzword for the past two or three decades and big data is the new trend in technology. A question that often arises in our mind is, “Are they similar and will Big Data replace a Data Warehouse”, the reason being, both have similarities like holding data, used for reporting purposes and managed by electronic storage devices. There is an underlying difference between the two, namely; Big Data Solution is a technology whereas Data Warehousing is an architectural concept in data computing.
An organization can have different combinations such as Big Data or Data warehouse solution only or Big Data and Data Warehouse solutions based on the four consideration factors such as: Data Structure, Data Volume, Unstructured Data, Schema-on-Read.
This blog post tries to bring out the similarities and differences between the two and illustrates with a Use Case example.
What is a Data Warehouse?
Data Warehouse is a conceptual architecture that helps to store structured, subject-oriented, time variant, non-volatile data for decision making. Data Warehouse typically stores the historical data, a copy of transaction data specifically structured for query and analysis. The physical data consolidation has been shifting to a more logical one which accommodates real time data as well. Data from the sources are transformed (cleansed, applying business rules, enhanced) and analysis is done in ETL/ELT phase to load into a structured form (Can be relational, dimensional, hybrid etc...).
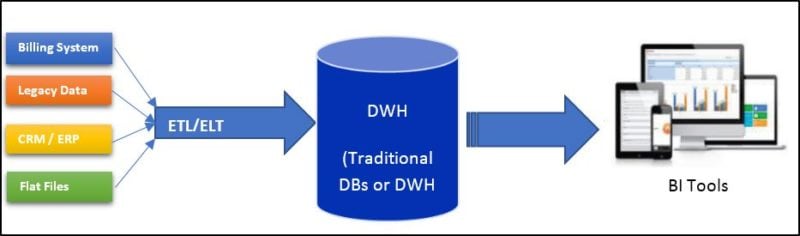
Figure 1: Traditional EDW Architecture
A traditional Data Warehouse integrates data from many transactional and operational systems, to present the resulting information as a “single integrated version of the truth” to decision makers at all levels of the organization. The design of the data warehouse, if done properly, allows us to access, report and analyze that information from all the relevant and possible angles; which drives consistent and accurate information as a result.
What is Big Data?
Big data is a technology that is used to store the unstructured data from various sources and to manage huge volume of data in Exabytes (size of west coast states) and Zettabytes (size of Pacific Ocean). Big Data is capable of storing structured, semi-structured and unstructured data comprising of video, audio, unstructured text, etc. using less expensive storage devices. The processing of data is decentralized and distributed across multiple servers for faster processing. There is no schema or modelling to the data stored and the data is stored in its native format. The actual usage will be done by applying rules to this data and report will be obtained.
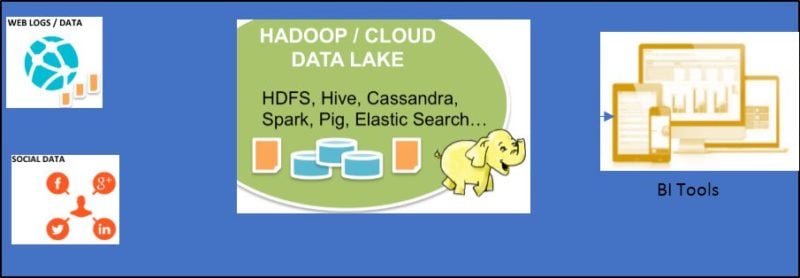
Figure 2: Big Data Warehouse Architecture
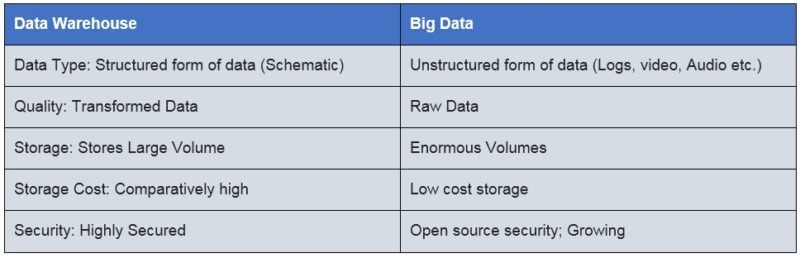
Comparison table of Data Warehouse to Big Data
Choosing Data Warehouse or Big Data:
Current day's data is not only large in size but characterized by 4V’s (Volume, Velocity, Variety, Veracity) that has changed the way the data is consumed radically. To cite an example, Facebook reported that nearly 2.5 billion different items are shared each day and their data is growing at a rate of 500TB daily and they claim to capture each user’s click in their storage space. Typically while dealing with such big data analytics projects, failures are also common.
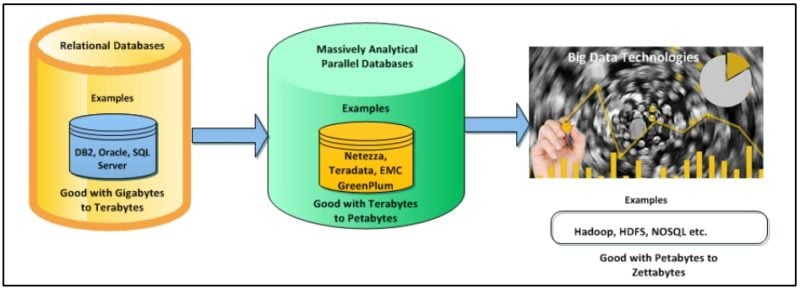
Figure 3: Data Warehouse to Big Data
So, as organizations have grown, there emerges the challenge to store and extract value information from these data which involves cost, quality, accuracy and maintenance. The traditional data warehouse is typically implemented in a single or multiple relational database serving as a central repository. Unlike traditional data warehouses, massively parallel analytic databases such as Netezza, Teradata, EMC GreenPlum are capable of quickly ingesting large amounts of mainly structured data with minimal requirement of data modeling, and scale-out to accommodate multiple terabytes to petabytes of data. Most importantly for end-users, massively parallel analytic databases support near real-time results to complex SQL queries. And, it is good with ELT instead of ETL.
In contrast, Big Data technologies are designed to span multiple machines and handle huge volumes of data irrespective of structured, semi-structured or unstructured data with high performance in cloud-based environment or distributed servers using Hadoop, HDFS, NOSQL etc.
With respect to business usage view, the reports are readily accessible by business from the EDW but limited to only structured and transactional data. Also, the information present at all levels in DW can be fetched based on needs because of the structural arrangement of data. If business requires additional information which is available in social media, logs then it requires rebuilding of the DW depending on the requirement. The business analyzes on each piece of raw data and requires separate transformations on the Big Data to build a report. This involves cost and extra efforts. The retrieval of information present in Big Data is difficult as the data present is unstructured and not organized.
Financial services companies generate structured data such as customer demographics and transaction history, and unstructured data such as customer behavior on websites and social media. In cases where organizations rely on time-sensitive data analysis, a traditional database DWH is a better fit for structured customer demographics and transaction history. On the other hand, where fast performance isn’t critical, Big Data analysis is fit for all structured and unstructured customer transaction or behavioral data.
Can Big Data/Hadoop and EDW share the same umbrella?
Increasingly, organizations understand that they have a business requirement to combine traditional data warehouses, with their historical business data sources at one end and less structured and big data sources at the other end. A hybrid model, supporting traditional and big data sources, can thus help accomplish these business goals.
In this hybrid model, the highly structured optimized operational data remains in the tightly controlled data warehouse, while the data that is highly distributed and subject to change in real time is controlled by a Hadoop-based infrastructure. Teradata Aster Big Analytics Appliance - is the first of the kind to embed SQL and big data analytic processing to allow deeper insights on multi-structured data sources with high performance and scalability.
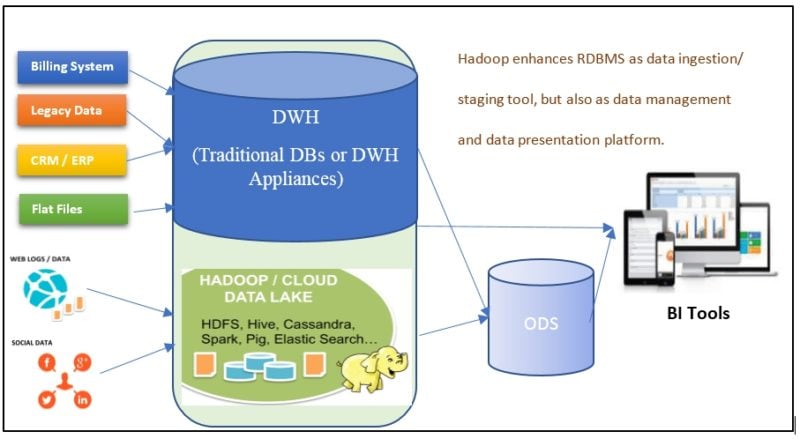
Figure 4: Hybrid DWH Model
More over the hybrid approach allows firms to protect their investment in their respective DWH infrastructure and extend it to accommodate the Big data environment. As Hadoop is a family of products, each with multiple capabilities, there are multiple areas in data warehouse architectures where Hadoop products can contribute like Data Staging, Data Archiving, Schema Flexibility etc. Hadoop seems most compelling as a data platform for capturing and storing big data within an extended DW environment, in addition to processing that data for analytic purposes on other platforms.
One of the approaches to amplify DWH in an Enterprise with Hadoop/Big Data cluster is as follows:
- Continue to store structured data from OLTP and back office systems into the DWH.
- Store unstructured data i.e. all the communication with customers from phone logs, customer feedbacks, GPS locations, photos, tweets, emails, text messages into Hadoop/NoSQL that does not fit nicely into tables.
- Co-relate data in DWH with the data in the Hadoop cluster (can be loaded into ODS also) to get better insight about customers, products, equipment, etc. Organizations can now run ad-hoc analytics and clustering and targeting models against this co-related data in Hadoop, which is otherwise computationally very intensive.
Conclusion
While Big Data technologies are focused on advanced analytics, a modernization strategy for data archives, the EDW environment was mostly built for reporting, OLAP and performance Management. Hence we can rightly state that Big Data is a complement not a replacement to a data warehouse. They co-exist based on the business requirements.
Hadoop will not replace a data warehouse because the data and its platform are two non-equivalent layers in Data warehouse architecture. However, there is more probability of Hadoop replacing an equivalent data platform such as a relational database management system.