




.jpg)

Overview
It is common practice to make changes to the underlying systems either to correct problems or to provide support for new features that are needed by the business. Changes can be in the form of adding a new source system to your existing Enterprise Data Warehouse (EDW).
This blog post examines the issue of adding new source systems in an EDW environment, how to manage customizations in an existing EDW, what type of analysis has to be made before the commencement of a project in the impacted areas, and the solution steps required.
Enterprise Data Warehouse
An Enterprise Data warehouse (EDW) is a conceptual architecture that helps to store subject-oriented, integrated, time-variant, and non-volatile data for decision-making. It separates the analysis workload from the transaction workload and enables an organization to consolidate data from several sources. An EDW includes various source systems, ETL (E- extract, T - transform, and L - load), Staging Area, Data warehouse, various Data Marts, and BI reporting as shown in EDW Architecture.
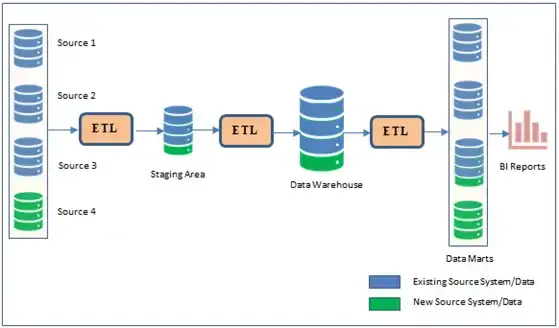
Figure 1: Enterprise Data Warehouse Architecture
Why do we need to add a new source system/data in an existing EDW?
An organization can have many transactional source systems. At the time of building EDW, the organization may or may not consider all the source systems. But over time, they need to add those left outsource systems or newly arrived source systems into the existing EDW for their decision-making reports.
Challenges in Adding a New Source System/Data to the existing EDW
Let us illustrate with a real-time scenario.
Let us assume that the existing EDW has the below data model as shown in (Figure 2: Existing EDW Data Model). The business has decided to add data from a new source system (Figure 1: Source 4) to the existing EDW. This new source system will be populating data into all the existing dimension tables and also has some more information, which requires storing in a new dimension table (Figure 3: Store Dimension).
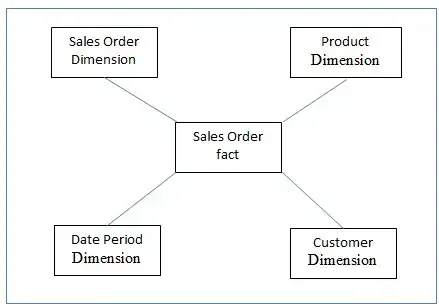
Figure 2: Existing EDW Data Model>
Adding data by creating a new dimension table in the EDW does not pose an issue because we will be able to create new ETL jobs, staging tables, DIM tables, Marts, and Reports accordingly.
Pain Point
The problem arises when we try populating new source data into the existing DIM/Fact tables or in Marts in EDW without proper analysis. This may corrupt the existing ETL jobs, upstream and downstream applications, reporting process, and finally corrupting the EDW.
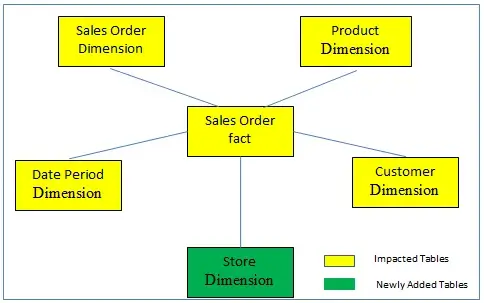
Figure 3: EDW Data Model after adding a new source system
What kind of analysis must be performed before commencing a project?
Analysis has to be performed in the below-mentioned areas:
New Source System/Data
Any organization that has many lines of business globally or locally stores the data in multiple source systems. No two source systems will be completely identical in terms of the data model, tables ddl (data definition language), and information stored.
Before introducing a new source system to the EDW, data has to be analyzed at the row and column level (maximum length, type, and frequency of the data). It is recommended to use any profiling tool (like IDQ or IBM IIA) to get a complete picture of your data.
Target DIM/Fact tables
It is crucial to have a complete picture of the existing EDW DIM/Fact tables of which the new source system data will be a part.
Accommodating the new Source System Data
Most of the EDW Table column types are defined as INTEGER, but the problem arises when the new source system has the data type as ‘BIGINT”. It is a known fact that BIGINT value cannot reside in an INTEGER field.

In this scenario, we had to change the schema of the existing DW table from INT to BIGINT. However, we must ensure that there is no impact on the existing data received from other source systems.
Similarly, we found many changes required in the existing EDW to accommodate the new source system data.
Mapping
After completing the analysis of source and target tables, we have to create the BIBLE (mapping document) for smoothly marrying the new source system to the existing EDW. It should clearly have defined what ddls need to be changed in the staging and Target DB tables.
Changing the ddls of the table is not an easy task because the table already has a huge volume of data and is indexed. It is recommended to consult a Database Architect or perform under the supervision of an expert.
ETL Jobs
Any changes in the existing target table ddls will bring huge ripples in the ETL jobs. As we know, most of the EDW stores the data in SCD2/SCD3. For implementing SCD2/SCD3, we use lookups in target tables. In the above scenario, we modified the target table column datatype INTEGER to BIGINT. But what will happen with the existing ETL jobs that were doing a lookup in the same table and expecting an INTEGER datatype? Obviously, it will start failing. So, it is mandatory to do a rigorous impact analysis of the existing ETL jobs.
Upstream and Downstream Applications
The data stored in the EDW is uploaded from the upstream applications and consumed by downstream applications like reporting and data analysis applications. Any changes in ETL jobs or in EDW will impact these applications. Without doing a proper impact analysis of these applications and adding new source data in the existing EDW can impact adversely.
Conclusion
Mastech InfoTrellis’ 11-plus years of expertise in building MDM, ETL, Data Warehouse, and adding new source systems/data to an existing EDW have helped us to perform a rigorous impact analysis and arrive at the right solution sets without corrupting the EDW.